Detrended Fluctuation Analysis (DFA)で,ホワイトノイズを解析したらどうなるか,数値実験で確かめてみます.理論的な結果は,前の記事を参照してください.
chaos-kiyono.hatenablog.com
数値時系列の生成
Rでホワイトノイズを生成するのに,以下のスクリプトを使います.スクリプトを実行すれば,xに時系列ベクトル,sigに推定した標準偏差が入ります.
# 時系列の長さ N <- 10000 # 正規乱数の生成 x <- rnorm(N) # 標準偏差を推定 sig <- sd(x)
1次DFA
計算は速くないですが,Rで1次のDetrended Fluctuation Analysis (DFA1)を実装してみます.使ったスクリプトは以下です.xにホワイトノイズのサンプル時系列が入っている必要があります.
#
# xを時系列ベクトルとする
#
N <- length(x)
###############################
# 平均0化
x <- x - mean(x)
# 積分
y <- cumsum(x)
###############################
# scalesの設定
scale.min <- 3
scale.max <- N/4
scale <- unique(round(10^seq(log10(scale.min),log10(scale.max),0.05)))
n.scale <- length(scale)
###############################
F2 <- c()
for(i in 1:n.scale){
i.sub <- seq(1,N,scale[i])
n.sub <- length(i.sub)-1
F2[i] <- 0
ii <- 1:scale[i]
for(j in 1:n.sub){
y.sub <- y[i.sub[j]:(i.sub[j+1]-1)]
fit <- lm(y.sub~ii)
a0 <- fit$coefficients[[1]]
a1 <- fit$coefficients[[2]]
F2[i] <- F2[i] + mean((a0+a1*ii-y.sub)^2)
}
F2[i] <- F2[i]/n.sub
}
###############################
# 結果のプロット
# 実用の場面では,スケーリング領域を各自設定して,傾きを推定してください
par(mfrow=c(1,1),pty="s")
fit <- lm(log10(F2)/2~log10(scale))
plot(log10(scale),log10(F2)/2,col=4,,xlab="log10 s",ylab="log10 F(s)",main="DFA1")
# 理論的なスケール依存性
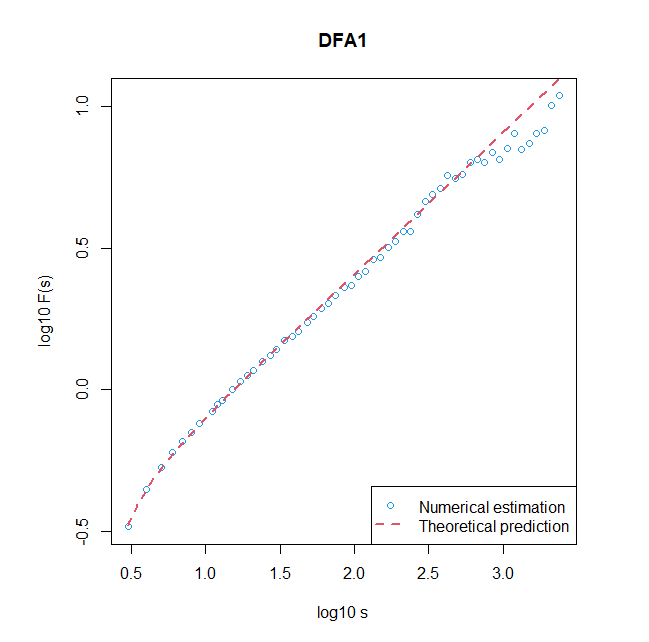
curve(log10(sig*sqrt(((10^x)^2-4)/(15*(10^x)))),xlim=c(log10(scale.min),4),log="xy",col=2,lty=2,lwd=2,las=1,add=TRUE)
legend("bottomright",legend=c("Numerical estimation","Theoretical prediction"),pch=c(1,NA),lty=c(NA,2),col=c(4,2),lwd=c(1,2))下の図が実行例です.小さいスケールで,理論的結果と数値実験結果が良く一致しています.
2次DFA
次は,Rで2次のDetrended Fluctuation Analysis (DFA2)を実装してみます.使ったスクリプトは以下です.今回も,xにホワイトノイズのサンプル時系列が入っている必要があります.
#
# xを時系列ベクトルとする
#
N <- length(x)
###############################
# 平均0化
x <- x - mean(x)
# 積分
y <- cumsum(x)
###############################
# scalesの設定
scale.min <- 4
scale.max <- N/4
scale <- unique(round(10^seq(log10(scale.min),log10(scale.max),0.05)))
n.scale <- length(scale)
###############################
F2 <- c()
for(i in 1:n.scale){
i.sub <- seq(1,N,scale[i])
n.sub <- length(i.sub)-1
F2[i] <- 0
ii <- 1:scale[i]
for(j in 1:n.sub){
y.sub <- y[i.sub[j]:(i.sub[j+1]-1)]
fit <- lm(y.sub~ii+I(ii^2))
a0 <- fit$coefficients[[1]]
a1 <- fit$coefficients[[2]]
a2 <- fit$coefficients[[3]]
F2[i] <- F2[i] + mean((a0+a1*ii+a2*(ii^2)-y.sub)^2)
}
F2[i] <- F2[i]/n.sub
}
###############################
# 結果のプロット
# 実用の場面では,スケーリング領域を各自設定して,傾きを推定してください
par(mfrow=c(1,1),pty="s")
fit <- lm(log10(F2)/2~log10(scale))
plot(log10(scale),log10(F2)/2,col=4,,xlab="log10 s",ylab="log10 F(s)",main="DFA2")
# 理論的なスケール依存性
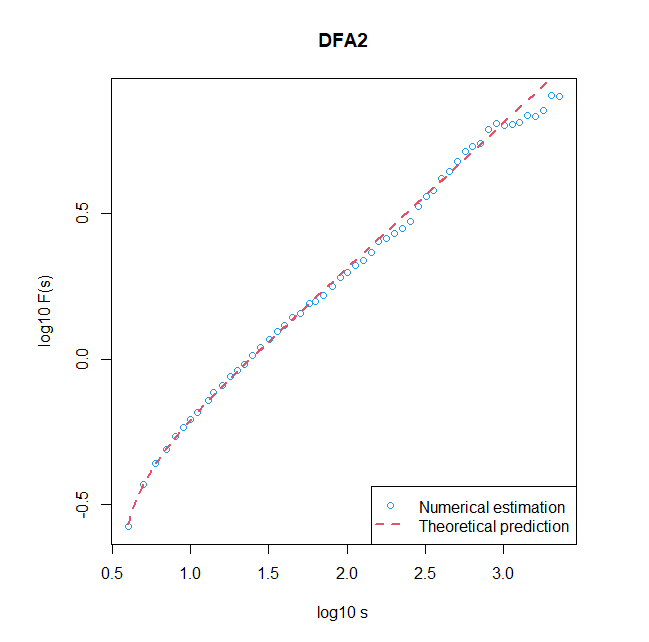
curve(log10(sig*sqrt((3*(10^x)^2-27)/(70*(10^x)))),xlim=c(log10(scale.min),4),log="xy",col=2,lty=2,lwd=2,las=1,add=TRUE)
legend("bottomright",legend=c("Numerical estimation","Theoretical prediction"),pch=c(1,NA),lty=c(NA,2),col=c(4,2),lwd=c(1,2))下の図が実行例です.直線からのズレは,DFA2の方が,DFA1よりも大きく見えます.